21-06-2021
What is GraphQL? Get to know this alternative to create API
By Rodrigo Almeida, Middleware Developer @ Xpand IT
GraphQL is a query language for APIs, created and open-sourced by Facebook in 2015. Being database and data-source agnostic means it can be used effectively in any context where an API is used and allows the user to cope with the need for speed, flexibility and efficiency in client-server communication. So, how does GraphQL accomplish this? There are many ways to implement architecture around it…
- GraphQL server with a connected database. This is a single Web server that implements the GraphQL specification, where when a query payload is read and processed by the server, it fetches the required information from the database. Then it constructs the response object as described in the specification and returns it to the user. GraphQL can be used with any available network protocol, whether it’s TCP, WebSockets, etc…
- GraphQL as a layer integrating multiple systems. This is a particularly compelling point for enterprises with legacy infrastructures and different APIs’s with a high maintenance burden. A GraphQL API can unify these existing systems, hiding their complexity, which allows for new client applications to be developed that simply communicate with the GraphQL server to fetch the data needed. The server is then responsible for fetching data from the existing system and packaging it in the response.
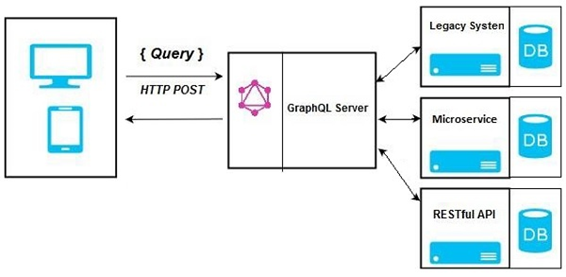
- Hybrid approach. Has a connected database but still communicates with legacy or other third-party systems.
Features
Fundamentally, GraphQL allows the user to specify what data it needs from an API by using declarative data fetching. This means that instead of having multiple endpoints returning structured data, GraphQL sends a single POST request to the server in which it describes all the data requirements using a strong type system to define the capabilities of the API. All the types exposed in an API are written using the GraphQL Schema Definition Language, which defines how the user can access the data. Here is an example of how you can make use of the SDL to define a simple type, in this case, a “Person” with basic information (the ! character after the type means that this field is required must be filled).
type Person {
name: String!
age: Int!
id: String!
}
We can also start building relationships between types., Let’s say that “Person” can be associated with one or more bank accounts and we can add additional info.
type Account {
currency: String!
details: Person!
}
Next, we need to add the other end of the relationship back to the “Person” type:
type Person {
name: String!
age: Int!
id: String!
accounts: [Account!]!
}
When it comes to fetching data, GraphQL functions differently from REST, and since the structure of the data is not fixed, the user is required to send more information to the server to express their needs. Let’s say for example that we want to return all the names of the Persons stored in the database:
{
allPersons {
name
}
}
allPersons, in this case, is the root field of the query, everything that follows it is the payload and the only field specified in that payload is the Ppersons’ name, so an example response would be as follows:
{
"allPersons": [
{ "name": "name1" },
{ "name": "name2" },
{ "name": "name3" }
]
}
If we want additional information, we can do something slightly more elaborate:
{
allPersons {
name
age
account {
currency
}
}
}
Lastly, we can also create modify or delete data using Mutation. Let’s create a new Person:
mutation {
createPerson(name: "name4", age: 99) {
name
age
id
}
}
In this case, not only are we creating a new Person but we’re also querying information while sending mutations, allowing users to retrieve new information from the server in a single round trip. Another interesting feature of GraphQL is that types have unique ID’s generated by the server whenever new objects are created, hence why we can also ask for a Person’s specific ID when it’s created and we don’t need to pass it as an argument.
GraphQL vs REST
REST has been the standard when it comes to building and designing API’s, focusing mainly on longevity and decoupling it as much as possible from the client. REST also presents a strict specification and one of the main reasons for using GraphQL lies within the inflexibility of REST to keep up with the rapidly changing requirements of the clients that consume such API’s.
The main reason Facebook uses GraphQL is to minimise the amount of data it needs to be transferred over the network, and an increasingly mobile usage creates a need for this efficient data loading. and Server-defined representations of resources don’t serve this scenario well. Another point of emphasis is the variety of different front-end frameworks and platforms on the client side, making it difficult to build an API that fits varied requirements of all different kinds, and developers also have to design the API endpoints while bearing the front-end views in mind, and changes to the front-end views require changes to the API endpoint. This lack of flexibility means a slower product iteration.
REST APIs often returned more data than what the client needed (over-fetching), alternatively, the client had to make multiple API calls to get all the data it needed (under-fetching). Both these issues might become troublesome for a company facing performance or scalability issues since with each change in the front end there is a risk that more or fewer data will be required than before; therefore, the back end also needs to be adjusted to accommodate the new data needs. This kills productivity and slows down the development of the product itself.
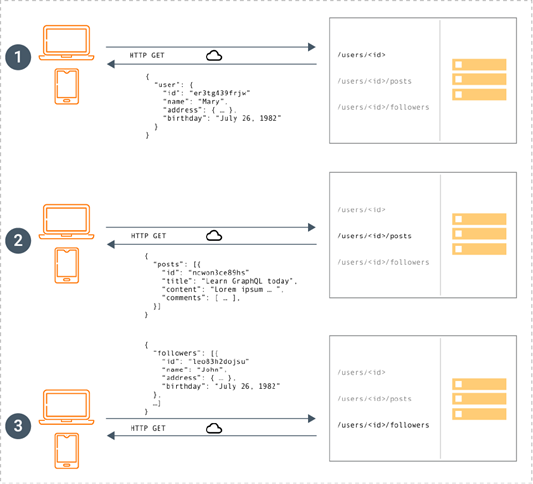
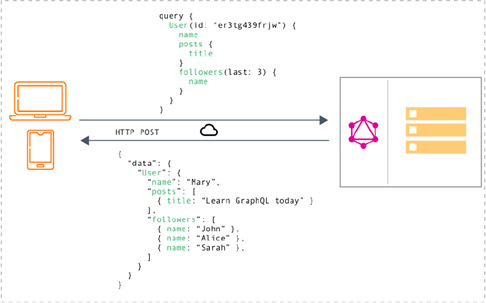
GraphQL has the tools to enable developers to design API calls that meet their specific data requirements. This way, GraphQL resolves the over-fetching and under-fetching challenges. Below you can see how REST and GraphQL handle getting data. REST needs information from 3 different endpoints, these could be /users/<id> endpoint to fetch the initial user data. Secondly, there’s likely to be a /users/<id>/posts endpoint that returns all the posts for a user and the third endpoint will then be the /users/<id>/followers that returns a list of followers per user. GraphQL on the other hand only needs to perform one query to return all the info required.
REST
GraphQL
Another point in where GraphQL shines is in tracing and analytics, giving detailed information about what data is read by users and requested in the back end, as each user can specify what information they want to are intent on fetching. This helps to understand how the available data is being used and improves the API, since you can deprecate specific fields that are not being used without much trouble, helping reducing bottlenecks in the systems. In REST, since all the entire data is returned every time, the application owner cannot truly know the usage of specific data elements.
GraphQL, on the other hand, uses queries, and so as it’s possible to retrieve specific data, therefore it’s also possible to track the performance of the system at the level of these resolvers, and find out whether the system needs tuning for better performance tuning.
Final thoughts
No… GraphQL has not made REST obsolete, nor should it replace it entirely, since there are still some areas in which REST still proves superior, like for example file transfers, HTTP caching to avoid re-fetching resources, debug proxies, etc…
So why not use both? One option would be for example using a GraphQL endpoint to a REST API and use that GraphQL endpoint or having one GraphQL API masking as a gateway to other REST API’s. It’s all about using the right tech for the right situation. All in all, what’s best is that there is a new alternative to REST when designing APIs.