
20-10-2022
How can a developer improve data quality?
by José Miranda, Data Analytics Engineer @ Xpand IT
We live in the age of data. Surely most people have a firm grasp of their importance as big companies like Google, Meta, Microsoft, among others, fight amongst themselves to win the throne of the data kingdom. But I do not think we can dwell on this world solely for the monetised way. The truth is that companies that seek to launch quality products or services that result in reliable knowledge for value creation, are and will be the most relevant and with which we can change the world.
And why do I say this? Did you know that 75% of developers and engineers who develop software and systems assume responsibility for data quality? Because today we are concerned with issues such as:
- The environment and what the future holds for generations
- The oceans and how to protect them by renewing reefs
- Financial markets and how to optimise them for the benefit of all stakeholders
- Supply chains and how to make them more efficient with less waste and exploitation of resources
- Energy, exploring cleaner options in order to make human beings less polluting
- Marketing, by trying to know in what terms a broad solution can be offered or what positioning to use for each segment
- And in the business fabric, by analysing how business processes can be improved, making them more attractive to the market, to their human resources and to public opinion
There are many more, but these are a few examples just to make the case that all these issues, if not all, will be answered with data – information needed for taking the right approach when in the hands of the right people.
I like to use these analogies. When driving, you are very likely to use GPS apps. So, imagine you are going on a journey. Imagine that the GPS tells you to turn onto a road, which, although faster, is full of holes, which will cause you to flatten one of the front tyres. Although the GPS was sending you on a faster route, it did not expect you to have a flat tyre on that road. This one example of information which is partly correct and partly incorrect.
In a more real sense, we had one case with a client where we wanted to build a chart that listed the budget for each innovation project. In other words, we wanted to be able to understand which projects had obtained the most budget in each year or per department. The fact of the matter is that we were getting completely absurd and faulty figures. And what is the reason for all this? Nothing more than the difference between a comma and a full stop. In fact, the platform from which we took the data returned the thousand separator as a comma, whereas in the tool where we built the graphs, that comma corresponded not to thousands but to decimals. Faced with this scenario, we would have two solutions: either we would change the format at the source, or in the data processing we would create a rule that would change the commas for dots and vice-versa. In the end, the solution was to create the rule.
So how can you know that the data is right? Become a Data Engineer or assume an equivalent position and follow some of the points that you should take into account to ensure the quality of the data:
- First of all, try to understand who the stakeholders are and what your role is. You must always know who is responsible for the data and who creates it so that you can address the right people whenever you have a question
- Ask the right questions. Understand well what you want to know and rigorously define the questions that will get the knowledge you look for
- Once you have the answers you are looking for, you will have data and it is from this point onwards that you will have to start being meticulous and treat this data in such a way as to avoid duplicate or misplaced fields, wrong types of data, etc. This video provides a good process example on data quality
- Also, make sure that the rules you want and the calculations you intend to do are well executed and returning the correct values. It only takes one badly done formula for all the values to go wrong.
- Having the data normalised and cleaned up, make sure you have a way of cataloguing that data to avoid redundancy. One dynamic allows you to create a table yourself and update it manually, or you can use a more modern approach, using software that offers data catalog and data lineage functionalities, as well as other functions in which you can define Machine Learning or Artificial Intelligence rules.
Lumada Data Catalog by Hitachi
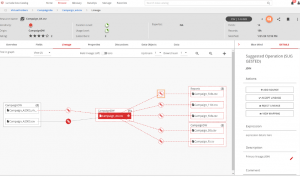
Purview by Microsoft
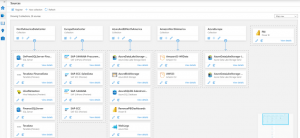
- Once you have the whole system articulated, try to notice patterns of errors or recurrently mis-entered data. Report to the person or team who may be the source of these errors so that they can be mitigated. If this is impossible, create rules in your system that consider the possibility of such errors
Conclusion
Ensuring the quality of our processes is not always easy and making sure the data is largely clean giving correct calculations and no duplicates is often a big headache as we don’t always notice everything, but easily mastered when we become the data Hercules. The information above mentioned is just the basics and the beginning of a great process which you can find on sites such as Dataversity or on YouTube videos about Quality Data Management.
What are you waiting for? Join us and help us to make the world a better place.


















Leave a comment
Comments are closed.